...that we, as the canonical source for the original questions and answers, would always rank first...That's why Joel Spolsky and I were confident in sharing content back to the community with almost no reservations – because Google mercilessly penalizes sites that attempt to game the system by unfairly profiting on copied content.Jeff Atwood's post goes on to argue that something is wrong with the way Google is ranking sites that derive content from other sites.
I was reminded of this post when I started to notice that searches for fairly obscure Australian animals would often return my own web site Australian Faunal Directory on CouchDB as the first hit. In one sense this is personally gratifying, but it can also be frustrating because when I Google these obscure taxa it's usually because I'm trying to find data that isn't already in one of my projects.
 But what I've also noticed is that the site that I obtained the data from, Australian Faunal Directory (AFD), rarely appears in the Google search results. In fact, there are taxa for which Google doesn't find the corresponding page in AFD. For example, if you search for Uxantis notata (shown here in an image from the Key to the planthoppers of Australia and New Zealand) the first hit(s) are from my version of AFD:
But what I've also noticed is that the site that I obtained the data from, Australian Faunal Directory (AFD), rarely appears in the Google search results. In fact, there are taxa for which Google doesn't find the corresponding page in AFD. For example, if you search for Uxantis notata (shown here in an image from the Key to the planthoppers of Australia and New Zealand) the first hit(s) are from my version of AFD:
Neither the original AFD, nor the Atlas of Living Australia (ALA), which also builds on AFD, appear in the top 10 hits.
Initially I though this is probably an artefact. This is a pretty obscure taxon, maybe things like rounding error in computing PageRank are going to affect search rankings more than anything else. However, if I explicitly tell Google to search for Uxantis notata in the domain
environment.gov.au I get no hits whatsoever: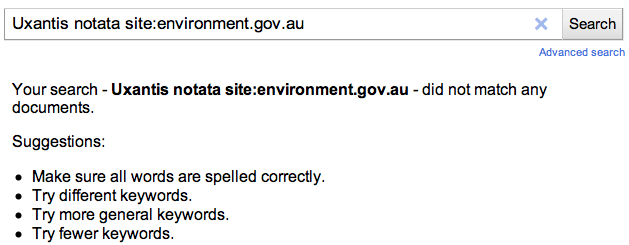
Likewise, the same search restricted to
ala.org.au finds nothing, nothing at all. Both AFD and Atlas of Living Australia have pages for this taxon, here, and here, so clearly something is deeply wrong. Why are the original providers of the data not appearing in Google search results at all? For someone like me who argues that sharing data is a good thing, and sites that aggregate and repurpose data will ultimately benefit the original data providers (for example by sending traffic and Google Juice) this is somewhat worrying. It seems to reinforce the fear that many data providers have: "if I share my data someone will make a better web site than mine and people will go to that web site, rather than the one I've created with my hard-won data." It may well be that data aggregators will score higher than data providers in Google searches, but I hadn't expected data providers to be virtually invisible.
If a web site that I hacked together in a few days does better in Google searches than the rather richer pages published by sites such as ALA (with a budget of over $AU 30 million), something is wrong. Unlike the Stack Overflow example discussed above, I don't think the problem here is with Google.
If we search in Google for an "iconic" Australian taxon by name, say the Koala Phascolarctos cinereus, Wikipedia is the first hit (which should be no surprise). ALA doesn't appear in the top ten. If we tell Google to just search the domain
ala.org.au we get lots of pages from ALA, but not the actual species page for Phascolarctos cinereus. This suggests that there is something about the way ALA's website works that prevents Google indexing it properly. I'm also a little worried that a major biodiversity project which has as its aim ...to improve access to essential information on Australia’s biodiversityis effectively invisible to Google.