Inspired by the forthcoming
Hack4Knowledge I've put together a service that enables you to assert that you are the author of a paper using the
Mendeley API.
If you are impatient, give it a try at:
http://iphylo.org/~rpage/hack4knowledge/iwrotethat/To use it you need a Mendeley account. When you go to
I wrote that you will be asked to connect to your Mendeley account. Once you've done that, enter the DOI or PubMed ID of a paper and, if the paper is in your Mendeley library and flagged as a paper you've authored, you should see something like this:
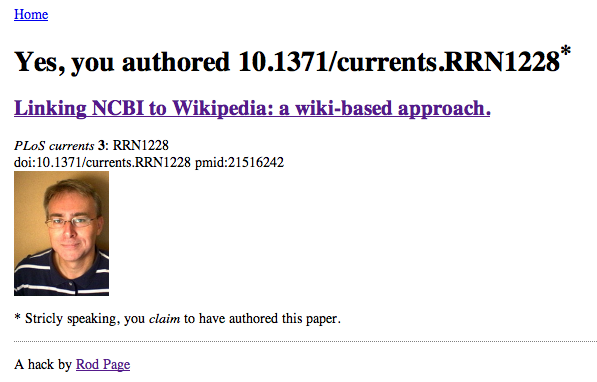
The site can be a little sluggish as it needs to go through all of your publications one by one until it finds a match.
Why?Imagine you have a web database that includes publications, and you want people to join your site as users. If they have publications in your database, you'd like your users to be able to say "I'm the author of those papers" or, more generally, the author you have as "Roderic D. M. Page" is me.
One way to do this would be to enable the users to sign in to your site using Mendeley (see my blog post
Mendeley connect). Once they've done that, the user could select a publication and say "that's mine". How do we test this assertion? Well, if the user is indeed the author it is likely that they will have added it to their "My Publications" section in their
Mendeley library. So, we can use the Mendeley API to get a list of the author's publications and see whether the publication they claim is, in fact, one of theirs.
The inspiration for this came from tools like Google Analytics, where in order to add the tool to your web site you need to convince Google that you own the site. One way to do this is to add some text supplied by Google to the HTML on for site, on the assumption that only you can do this (because it's your site). In the same way, only you can add papers to your Mendeley library. Of course, I'm assuming that Mendeley users are being trustworthy when they and papers to "My Publications" (i.e., they're not claiming authorship on papers they didn't write).
How?This hack uses Mendeley's OAuth support (the same technology used by Twitter and Facebook to connect to other sites) to enable you to connect your Mendeley account to the "I wrote that" application (note that my app never sees your account name or password). I use the Mendeley API
user authored method to get a list of your publications, and
user library document details to retrieve details of each publication. I then compare the DOI or PMID you supplied with each publication, until I find one that matches. If none matches, then I've no evidence you authored that paper.
MoanNo post about the Mendeley API would be complete without a moan about the state of the API. Apart from the fact that there is no function to directly find a publication in your library by DOI or PMID (hence I have to look at them all), there is virtually no support for retrieving any details about the user. For example, I wanted to brighten the web page up a little by adding a picture of the Mendeley user once they've logged in. There is no API function for this, nor a function to retrieve an identifier or URL for the user. Hence, in order to get a picture I screen scrape (yes,
screen scrape) the Mendeley web page for the reference to get the URL for the linked author of the paper, then scrape the author's profile page and extract the URL for the image. This is insane. Please, please can we have a better API?


{kind=link}