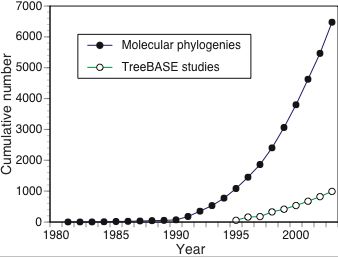
Bone Rooms, Bird Bodies, and Biodiversity Informatics is an old article now, but it's a nice summary of what biodiversity informatics is about.
Some people believe that museums contain only musty air, stuffy docents, and pure boredom. However, tucked away behind a mysterious door marked "Museum Staff Only" is a dynamic and ever-growing resource few of us are lucky enough to see in person: the museum collection itself. Whether you imagine graybeards stirring up dust as they pin shiny beetles into tiny boxes or a sparkling modern facility, every museum's beating heart is its hidden collection of specimens and associated library of descriptive notebooks. These collections are anything but boring, and many are now online.