
Monday, April 24, 2006
Ambient Findability
Sunday, April 23, 2006
Darwin hacked
One of my lab's web servers was hacked last week. This machine hosts a lot of projects, such as the Glasgow Name Server, the Taxonomic Search Engine, iSpecies, LouseBase, and TreeView X. Sadly, it was not completely backed up, although most of the key stuff is replicated elsewhere (including source code in CVS on another machine, or in SourceForge, copies of databases on other machines, etc.). Even if it was completely backed up, there is the hassle of rebuilding a machine. Still, since it wasn't backed up, here are some of the things I had to go through.

The kernel (Red Hat 8) had been tampered with, so the machine would no longer boot. I'm was now faced with the task of getting stuff off the machine in case reinstalling the operating system lost data. Luckily the machine (a Dell Precision 620) booted from a Knoppix CD, which gave me a GUI. So now I can browse my crippled machine, but...
 ... it couldn't talk to the Net because the Knoppix live CD uses DHCP to get an IP address, and my university doesn't support DHCP (argh!). However, I have an Apple Airport base station with a spare Ethernet port, and connecting the Dell to that port provided a DHCP address (yay).
... it couldn't talk to the Net because the Knoppix live CD uses DHCP to get an IP address, and my university doesn't support DHCP (argh!). However, I have an Apple Airport base station with a spare Ethernet port, and connecting the Dell to that port provided a DHCP address (yay).
Booting from a live CD has one major limitation -- I can't alter anything on the disks in the Dell. Hence, doing things like changing file permissions, or making tarballs to be able to FTP directories is out of the question. I don't have a USB key or an external USB hard drive big enough to take the gigabytes of stuff on the Dell.
What worked, after a lot of fussing was Samba. Using the smb:// protocol in Konqueror (I trick I learned from Mac OS X), I managed to connect to a Fedora Core 4 box in my lab. I could then drag and drop key files onto the FC4 machine (such as httpd.conf, hosts.allow, various CGI scripts, etc.) that were specific to the hacked machine. I also made backups of the home folders, just in case.
This left MySQL databases. Moving these proved to be a major pain, because they are not accessible by the Knoppix user. The solution turned out to be to mount the FC4 box using Samba:
Now we can copy all the MySQL databases on the FC4 machine.
Ah, but how to get the actual data...? Well, on my Mac OS 10.3 iBook, I have MySQL 4.0.21, which works with the MySQL files from Red Hat 8 (3.23 I think). I use CocoaSQL to create the database, then move all the .MYI and .MYD files into the appropriate folder in /Library/MySQL/data/, then set permissions to ensure that mysql can read the files (make user mysql the owner chown mysql *, and set permissions to 660).
Yes, the obvious lesson is to have everything backed up, but on a developmental machine with gigabytes of images and other data, much of it moved around frequently, and a central backup system whose client software wouldn't build on my machine, I'd sort of let this slip (doh!).
The kernel (Red Hat 8) had been tampered with, so the machine would no longer boot. I'm was now faced with the task of getting stuff off the machine in case reinstalling the operating system lost data. Luckily the machine (a Dell Precision 620) booted from a Knoppix CD, which gave me a GUI. So now I can browse my crippled machine, but...
... it couldn't talk to the Net because the Knoppix live CD uses DHCP to get an IP address, and my university doesn't support DHCP (argh!). However, I have an Apple Airport base station with a spare Ethernet port, and connecting the Dell to that port provided a DHCP address (yay).Booting from a live CD has one major limitation -- I can't alter anything on the disks in the Dell. Hence, doing things like changing file permissions, or making tarballs to be able to FTP directories is out of the question. I don't have a USB key or an external USB hard drive big enough to take the gigabytes of stuff on the Dell.
What worked, after a lot of fussing was Samba. Using the smb:// protocol in Konqueror (I trick I learned from Mac OS X), I managed to connect to a Fedora Core 4 box in my lab. I could then drag and drop key files onto the FC4 machine (such as httpd.conf, hosts.allow, various CGI scripts, etc.) that were specific to the hacked machine. I also made backups of the home folders, just in case.
This left MySQL databases. Moving these proved to be a major pain, because they are not accessible by the Knoppix user. The solution turned out to be to mount the FC4 box using Samba:
- su
- mkdir /mnt/linnaeus
- mount -t smbfs -o username=xxxx //linnaeus.zoology.gla.ac.uk/xxxx /mnt/linnaeus
Now we can copy all the MySQL databases on the FC4 machine.
Ah, but how to get the actual data...? Well, on my Mac OS 10.3 iBook, I have MySQL 4.0.21, which works with the MySQL files from Red Hat 8 (3.23 I think). I use CocoaSQL to create the database, then move all the .MYI and .MYD files into the appropriate folder in /Library/MySQL/data/, then set permissions to ensure that mysql can read the files (make user mysql the owner chown mysql *, and set permissions to 660).
Yes, the obvious lesson is to have everything backed up, but on a developmental machine with gigabytes of images and other data, much of it moved around frequently, and a central backup system whose client software wouldn't build on my machine, I'd sort of let this slip (doh!).
Tuesday, April 18, 2006
Render DOT files on the fly on Mac OS X
Webdot isn't available for Mac OS X, and as I use an iBook running Panther for all my development work (before moving to a Linux box to host the results) I wanted to have the same functionality on my iBook. This can be achieved by hacking a simplified version of webdot. This Perl script creates a virtual web browser to serve the image. I've simplified things somewhat, but it works.
The two things you need to set in the script dot.cgi are the path to your copy of the Graphviz program dot,and a directory where dot can write temporary files (I use /tmp).
You can get a copy of the script here.
To render an image of a graph on the fly you insert an img
tag with the src attribute comprising:
As an example, here is the dot file http://localhost/~rpage/dot/leda.dot as a PNG image, using the HTML:
<img src="/cgi-bin/dot.cgi/http://localhost/~rpage/dot/leda.dot.png" />

The source file for this graph looks like this:
The two things you need to set in the script dot.cgi are the path to your copy of the Graphviz program dot,and a directory where dot can write temporary files (I use /tmp).
You can get a copy of the script here.
To render an image of a graph on the fly you insert an img
tag with the src attribute comprising:
- the path to the CGI script, e.g. /cgi-bin/dot.cgi
- a '/' delimiter
- the URL of the graph file, e.g. http://localhost/~rpage/dot/leda.7.46.gml.dot
- the extension of the image format you want (e.g., png, svg, etc.) preceeded by a dot "."
As an example, here is the dot file http://localhost/~rpage/dot/leda.dot as a PNG image, using the HTML:
<img src="/cgi-bin/dot.cgi/http://localhost/~rpage/dot/leda.dot.png" />
The source file for this graph looks like this:
graph G {
node [width=.2,height=.2,fontsize=10];
edge [fontsize=10,len=2];
0 [label="0"];
1 [label="3"];
2 [label="4"];
3 [label="5"];
4 [label="6"];
5 [label="7"];
0 -- 1 [label="13"];
0 -- 2 [label="12"];
0 -- 5 [label="8"];
0 -- 4 [label="71"];
1 -- 5 [label="84"];
1 -- 4 [label="8"];
2 -- 5 [label="18"];
2 -- 4 [label="11"];
2 -- 3 [label="51"];
3 -- 4 [label="87"];
}
Sunday, April 16, 2006
YAKAFOKON: TreeMap Clustering in SVG with PHP
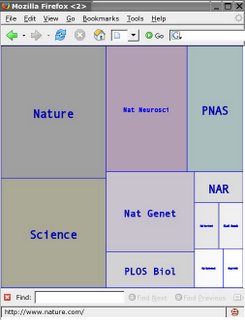
Pierre Lindenbaum has a very nice PHP script for generating Treemaps in SVG .
Saturday, April 01, 2006
Visualizing literature derived networks

We have developed PubNet, a web-based tool that extracts several types of relationships returned by PubMed queries and maps them into networks, allowing for graphical visualization, textual navigation, and topological analysis. PubNet supports the creation of complex networks derived from the contents of individual citations, such as genes, proteins, Protein Data Bank (PDB) IDs, Medical Subject Headings (MeSH) terms, and authors. This feature allows one to, for example, examine a literature derived network of genes based on functional similarity.
I've added it to my Connotea library under the tag visualisation (note to self: American English and British English spelling is just one of the problems with "tagging"). I'd seen this paper before, but "forgot" it until browsing Connotea and stumbling across nicmila's library. Nice illustration of the power of shared tags.
(Via nicmila.)
Currently playing in iTunes: Wisemen (Album Version) by James Blunt
Subscribe to:
Posts (Atom)