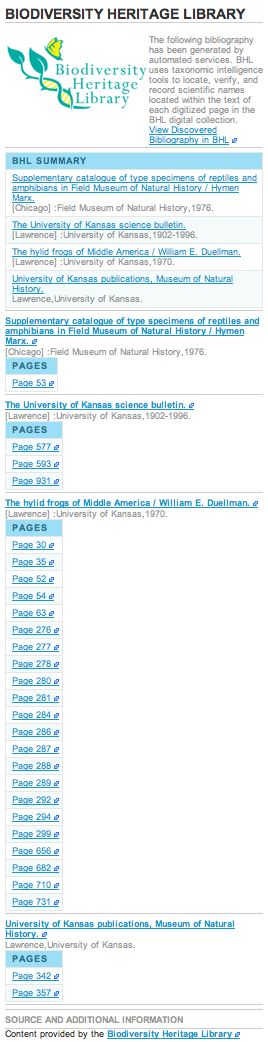
 One thing about the Encyclopedia of Life which bugs me no end is the awful way it displays the bibliography generated from the Biodiversity Heritage Library (BHL). The image on the right shows the bibliography for the frog Hyla rivularis Taylor, 1952. It's one long, alphabetical list of pages. How can a user make sense of this? It's even more annoying because the BHL is one of the cornerstones of EOL, and one could argue that BHL content is one of the few thing pages EOL offer that distinguishes them from cheap and cheerful mashups such as iSpecies. Can't we do something a little better?
One thing about the Encyclopedia of Life which bugs me no end is the awful way it displays the bibliography generated from the Biodiversity Heritage Library (BHL). The image on the right shows the bibliography for the frog Hyla rivularis Taylor, 1952. It's one long, alphabetical list of pages. How can a user make sense of this? It's even more annoying because the BHL is one of the cornerstones of EOL, and one could argue that BHL content is one of the few thing pages EOL offer that distinguishes them from cheap and cheerful mashups such as iSpecies. Can't we do something a little better?BHL has an API (documented here), so I decided to experiment. As I mentioned in an earlier post (Biodiversity Heritage Library, Google books, and metadata quality), a key piece of metadata about a bibliographic reference is its date. This is especially so for the taxonomic literature, where the earliest reference that contains a name may (depending on how complete BHL scanning is) be the first description of that name. So, it would be nice to order the BHL bibliography by date. Turns out it's possible to get dates from quite a few BHL items, providing one fusses with regular expressions long enough.
So, in principle we could sort BHL content by dates. But, we could go one better and visualise them. As an experiment, I've put together a demo that uses the SIMILE Timeline widget to display the BHL bibliography for a taxon. Here's a screenshot of the bibliography for Hyla rivularis:

You can generate others at http://bioguid.info/bhl/. The demo has been thrown together in haste, but here's what it does:
- Takes a taxon name and tries to find it in uBio. This gives us the NamebankID BHL needs
- Calls the BHL API and retrieves the bibliography for the NamebankID found in step 1
- Parses the BHL result, trying to extract dates (often the dates are ranges, e.g. 1950-1955)
- The previous step generates a JSON document which can be displayed by Timeline
If you click on an item you get a list of pages, clicking on any those takes to you to the page in BHL. Items that have a range of dates are displayed as horizontal lines, items with a well-defined date are shown as points. Note that my code for working out the date of an item will probably fail on some items, and some items don't have any dates at all. Hence, not every item in BHL will appear in the timeline.
It would be nice to embellish the results a little (for example, group pages into articles, refine the dates, etc.) but I think this goes a little way to demonstrating what can be done. We could also add articles obtained from other sources (e.g., Google Scholar, PubMed) to the same display, providing an overview of published knowledge about a taxon.