For example, the journal Breviora has most of its articles identified, mainly because the MCZ put a list of articles linked to BHL on their website. I harvested this to populate BioStor.

Other journals are looking a bit more sparse, such as the Bulletin of the British Museum (Natural History) (Entomology):
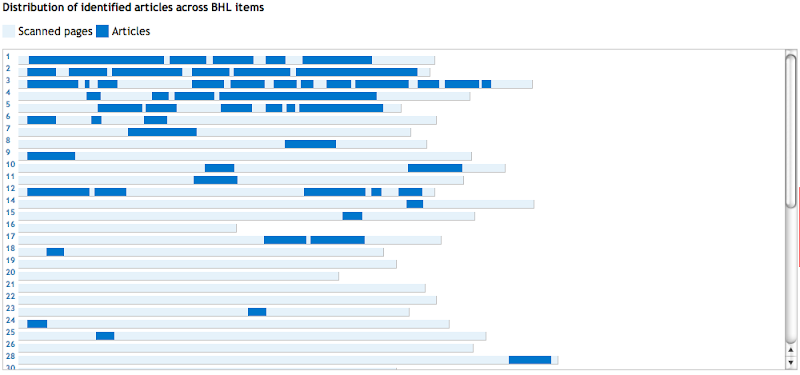
So, there's a lot to do, and a crying need for some combination of automation (whether driven by external metadata, which is my current approach, or trying to extract article information directly from the OCR text) and crowd sourcing if we're going to be able to make a significant dent in the task of finding articles in BHL.